One LLM call, repeated for every new headline. Replaced.
Obside is a French fintech that lets retail traders write strategies in plain English and fires the order when matching news arrives. Every headline × every active intent was a frontier-LLM call. TRACER moved 95% of it off GPT-5, without losing accuracy.
vs $0.00019 on GPT-5
parity-gated, never silent
labelled pairs
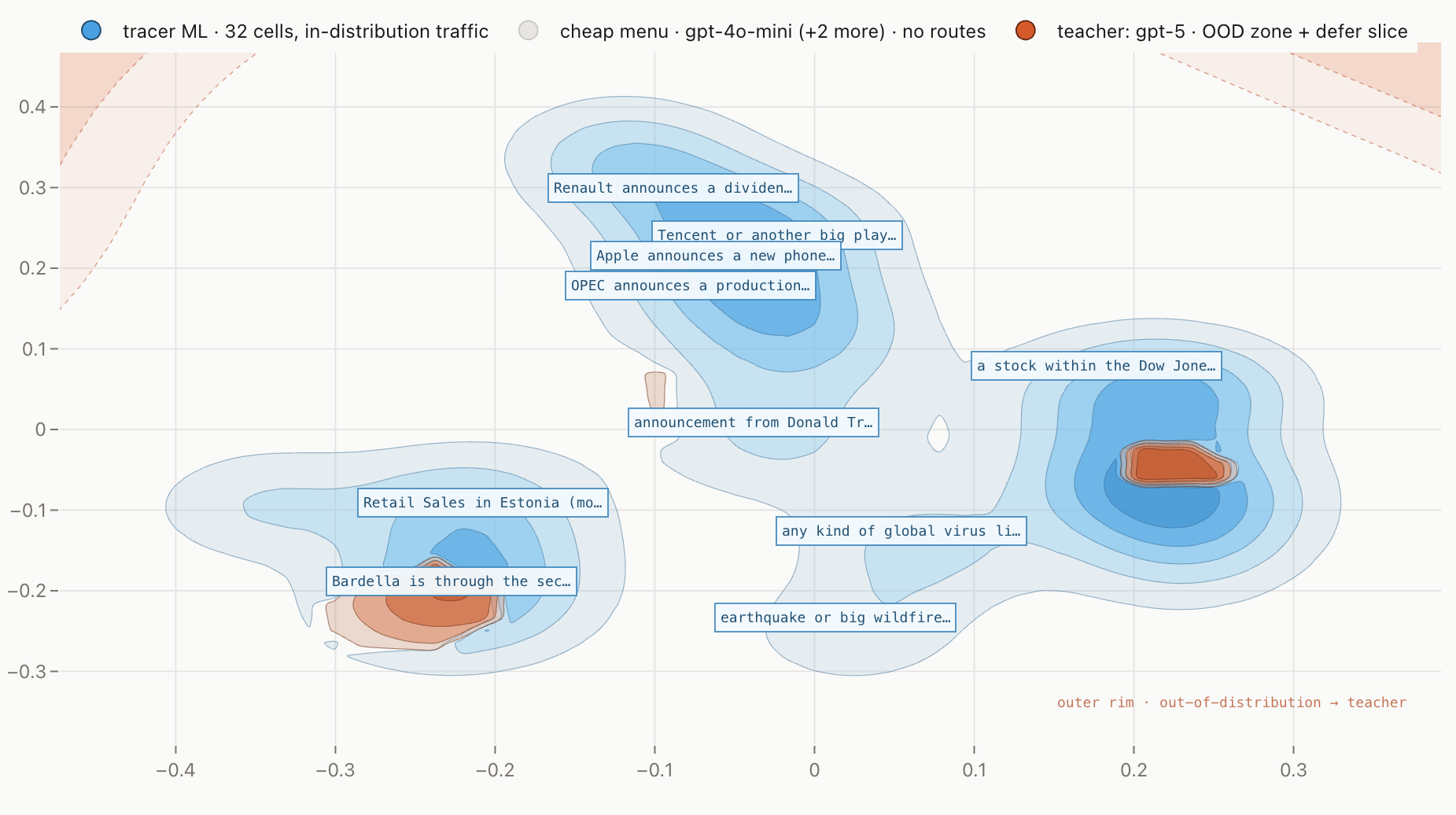
A cross product of user intents and news headlines
Each Obside user defines one or more strategies as natural-language
intents. As news comes in, every headline must be checked
against every active intent. The output is a single bit
per pair: match or no_match.
The volume grows with both user count and news velocity, fast enough that paying a frontier model per check stops making sense within months of launch. This is the canonical TRACER shape: one repeated decision with structured output, at scale, where the LLM is overqualified for the average case but indispensable on the long tail.
Teacher → 38-cell surrogate, with a tiered fallback
26,591 intent-news pairs labelled by the GPT-5 teacher Obside was
already running. A surrogate trained against the teacher's labels
on openai-3-small embeddings, partitioned into 38
cells via density clustering, gated by a second-stage acceptor.
The result is a tiered routing menu:
- 84% 32 cells → trained surrogate In-distribution traffic. Sub-10ms inference, near-zero cost. Auditable per cell.
- 11% Ambiguous cells → cheap-LLM menu GPT-4o-mini plus two siblings, for regions where the surrogate's confidence is uneven.
- 5% OOD zone → GPT-5 teacher Novel events the partition hasn't seen. Full frontier capacity, deferred only when needed.
Nothing was rebuilt in Obside's stack. The system sits behind an
OpenAI-compatible endpoint
(model="tracer-auto"), production version
20260511T053435Z took over routing without an outage.
Three versions have shipped to prod since.
38 cells emerge from the data, not from a taxonomy
The partition comes from the embedding space, each cell is a cluster of intents Obside users have actually written. The granularity is the user's, not ours. A few labels lifted directly from production:
What the classifier sees
Sampled from the production training corpus. The surrogate matches at the semantic level, not on string overlap.
Why frontier reasoning is overqualified here
Intent-news matching is a semantic similarity decision on a small, self-similar distribution of user-written queries. With a teacher's labels on tens of thousands of pairs, an embedding-space surrogate closes the gap to within 0.1 accuracy points, and the residual uncertainty becomes a deferral signal rather than a quality cost.
Paying for frontier reasoning on every headline is paying for a capacity that only the OOD tail actually needs.
"We moved the LLM out of the loop on 95% of matches and kept it for the calls that genuinely needed it. The savings are auditable per cell, not aggregated away."
Does your stack look like this?
If you can write the sentence "we use a frontier LLM to [classify / route / tag / match / triage / detect / score / choose] something that happens thousands of times per day," TRACER fits. Start with the open-source SDK, graduate to hosted when you're ready.